背景
传统编程模型认为写一个变量就是直接写了相应的内存地址,但是在现代计算机架构,简单点说CPU写的是cache lines而不是直接写内存,这些缓存大部分是L1一级缓存,也就是说CPU的一个核写的内容另外的核看不见,为了把变化广播给别的核(这样才能同样广播到别的线程),需要(做额外动作)把cache line的变化同步到其他核的cache.
JVM运行环境下,要做到上述的线程间共享,需要显式地给变量(memory locations)打上volatile 标记 或者使用Atomic原子包装数据结构,否则,一般变量值的变化不保证能实时同步给其它线程可见,要么就使用锁,你可能会问为什么不标记所有变量都是volatile的呢?因为在CPU的多个核之间同步cache lines是很昂贵的操作!会拖慢CPU内核速度并且导致cache coherence protocol (the protocol CPUs use to transfer cache lines between main memory and other CPUs) 瓶颈,结果就是明显的拖慢运行.
当你看源码时你以为的方法调用
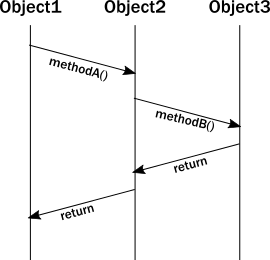
运行时一条线程执行你的代码时走的方法调用

两条线程的时候
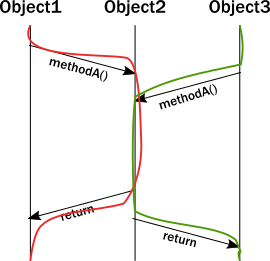
多条线程、多个对象、多种方法

曾经如日中天上有图灵奖背书下有Spring鼎鼎大名的OO编程,实际上对运行时环境是没有多大卵用的,OO多半只是源码这种文本的组织方式,类似书要分章节写作、货架要分品种摆放,到了编译之后的运行时二进制的世界里O只是一些方法和数据的包.
即使是对知晓上述情况的开发者,决定哪些memory locations应该用volatile标记或atomic结构,仍然也算是黑科技(框架或库的使用问题你可以google,但是并发问题都有各自的场景,加之往往很难再现,google不到标准答案,意指这些技能经验难以积累共享)
总之:
1、从来就没有什么真正共享的内存.一个CPU的多个内核之间传递数据 (cache lines)就跟不同计算机通过网络传递数据一个熊样!CPU间的通讯和网络通讯的共同点比大部分人所了解的要更多. Passing messages is the norm now be it across CPUs or networked computers.
2、把变量标记为共享(volatile)或使用atomic数据结构只是隐藏了消息传递而已(在多核之间或多个CPU之间传递消息).有节操有原则的姿势应该是把本地状态封装在并发实体当中,然后在并发实体之间传播数据或者事件——通过消息.
我们总是想当然认为方法调用自有其固定的调用栈,但是调用栈是上一个时代的产物,那个时代并发编程还不是主流,因为多CPU架构的系统不通用、不常见,调用栈Call stacks不会跨线程、无法对异步调用链建模.当一条线程要代理一项任务去后台运行,问题就暴露了,这不是一个简单的方法/函数调用,此时一个“caller”线程把一个对象放到一个内存位置,然后共享给另一条“callee”线程,callee线程接收到对象、会去执行某种事件循环也就是执行任务,caller线程也可以去干自己的事了.
第一个问题: caller线程怎么知道任务干完了?这还不算最严重的问题,更严重的是如果任务执行失败了呢?任务抛了个异常,但是是在 callee线程环境中抛的,callee线程该拿这个异常肿么办?没法办,这个异常只会传递给callee线程自己的exception handler异常处理器,因为它找不回当初的caller线程:
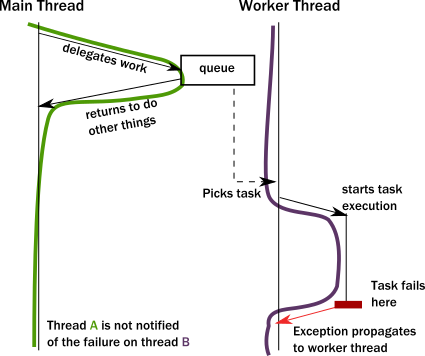
Main是caller线程;Worker是callee线程;caller调用了callee之后就一拍两散了,我不知你你不知我
只能用一些土办法,比如信号量之类的,但是如果信号迟迟不来,caller也毫无办法.实际上,在异常情况下任务就丢了、丢了?丢了!forever!这和网络通讯时messages/requests发生lost/fail丢失/失败情况是何其惊人的相似: 你得不到任何通知,没人会给你一个说法.In fact, due to the exception reaching to the top, unwinding all of the call stack, the task state is fully lost ! We have lost a message even though this is local communication with no networking involved (where message losses are to be expected).
在高并发系统当中,必然大量发生线程间代理/委托任务,而且这些代理必然也应该是无阻塞的(否则那不叫高并发),线程间所有协作都应该设置response deadlines也就是timeouts,和网络或分布式系统一样!
总之,对象和线程是两个维度的事情,OO没有理清它们,二者纠缠不清,这种OO是反人类的(你不觉得Gof设计模式大部分都怪怪的吗?),actor才符合我们的心智模型.
需要的话ActorSystem会使用大量线程,所以对每一个逻辑概念上的应用只要创建一个就好了,一个ActorSystem容纳几百万actor没问题.ActorSystem也管理着共享基础设施如调度服务、配置、日志等等,若干不同配置的ActorSystem可以共存在一个JVM里,AKKA本身并不存在全局共享状态(也就是不存在跨ActorSystem的共享),ActorSystem之间的actor还可以透明通讯,因此,ActorSystem本身(也像actor一样)可以用作系统构造块building blocks.
一个actor应该把大块的功能分解成更小的任务,交付给下属actor去并行完成,自己则专注于监管下级actor.所有actor都只有一个监管者,也就是创建它的那一个.actor系统最典型的行为特征就是任务分解、并行执行.设计这样一个系统的难点在于决定谁应该监管什么,一些指导原则:
1、任务的管理者应该监管任务的执行者,因为管理者知道这个任务可能出现什么样的失败以及如何处理.
2、如果一个actor携带有很重要的状态数据,那么它应该把一些危险任务委托给下级子actor去做,比如说为每个请求创建一个子actor(类似每请求每线程),这样也会简化结果收集状态管理,在ErLang中这就是著名的Error Kernel Pattern模式.
3、如果actor A需要依赖actor B分担它的职责,A应该观察(Watch)B的存活状态并对B的终止提醒消息进行响应,观察并不会干扰监管,这是另一套方法.functional dependency alone is not a criterion for deciding where to place a certain child actor in the hierarchy. 这句话意思应该是只有功能性依赖的话(也就是职责分担),是不能作为把某个actor放到监管层次某一个位置上的标准.总体来说,就是对于职责的分担而不是任务的分解可以用Watch、和监管无关的观察.
顶级actor筑成整个系统容错能力的内核Error Kernel,所以不可滥用,创建要节制、谨慎,更推荐真正层次化的系统,这样有利于故障处理/隔离(both considering the granularity of config and performance),同时还可以降低guardian actor监管actor的压力,当过载或使用不当时,guardian actor会形成单点争用瓶颈 —— 意思是应该创建少数顶级actor,一般也就1~3个左右,而且他们要慎用,不要去做有风险或阻塞的事情,只要做好它的角色就好,因为它们是当系统出现大范围故障时的最后火种,要仰仗它们恢复整个系统,要尽量多去分层,每层都有监管actor,把风险用多层的结构化解掉.
Erlang程序员说: 提高他们的程序的运行速度的技巧就是找出代码中需要顺序执行的部分.而对于任何对于其他编写顺序执行程序的程序员来说,提高他们程序速度的方法是找出他们程序中可以并行执行的部分.恩~,Akka’s Actors的API类似于scala Actor,然后它们又都是抄的ErLang: )
监管到底是啥意思?
supervision监管描述了一种actor之间的依赖关系,是一种递归的错误处理结构.监管者actor会把任务委托给下属actor去干,所以(和人类社会一样,下面人搞事儿那么监管者就得担事儿也就是要对下属的失败负责),当下属发生失败也就是抛出异常那么它会立即挂起suspend(不再处理消息,直到被恢复)自己以及它的所有下属,然后向监管者上报一个消息: 我搞不定了,老大您看咋办?老大也就是监管者有四个选项:
- 让下属继续/恢复工作(保留下属内部状态)- resume
- 重启下属(清空其内部状态) - restart
- 终止下属、forever!- stop
- 继续上报,从而也表明自己也搞不定了; - escalate
任何一个actor都必然属于某一个监管体系(actor不能独立存在只能存在于ActorSystem),也就是说所有actor都监管其他actor同时也被其他actor监管着(除了大boss根actor),这样一个体系下: 让下属继续/恢复工作也就是让下属的下属全部恢复工作、重启下属也就是让下属的下属全部重启;终止下属也就是让下属的下属全部终止——这便是递归的含义;actor的preRestart钩子方法默认就是终止所有下属(但该方法可以被重写),该方法执行完了才会递归重启所有下属.每个监管者都配置了一个翻译函数,函数将失败对应到上述某一个处理方式.但是这个函数没有接收actor ID参数,也就是说无法针对不同actor采取不同的策略,但是如果在一层想做的太多,是不利于reason about的,因此,更好的做法是添加一个监管层,也就是说实现层层监管,每一层的策略都是一致的.
AKKA的实现称做“强制父监管”,actor只能是由另一个actor所创建,顶级大Boss actor由库创建,其他所有actor都是由其创建者监管着的,无一例外.也就是说actor不可能没有监管者,也绝不可能被外界改变其监管者,这共同构筑了干净的actor监管逻辑树体系,actor监管树类似于操作系统管理进程构建的进程树类.注意: 监管相关消息使用独立邮箱,不会和常规业务消息混杂.actor逻辑树如下图示:
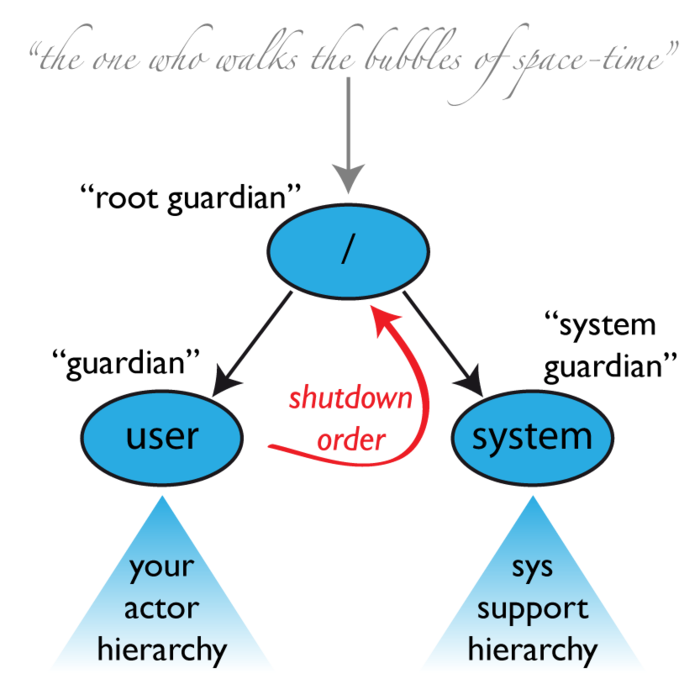
An actor system will during its creation start at least three actors
/user: 守护者
这个名为”/user”的守护者,是所有用户创建的顶级actor的父actor,可能是需要打交道最多的.使用system.actorOf()创建的actor都是其子actor,也是顶级actor.这意味着,当该守护者终止时,系统中所有的普通actor(也就是我们的业务actor)都将被关闭.同时也意味着,该守护者的监管策略决定了普通的顶级actor是如何被监督的.自Akka 2.1起就可以使用这个设定akka.actor.guardian-supervisor-strategy,以一个SupervisorStrategyConfigurator的完整类名进行配置.当这个守护者上报escalates一个失败,根守护者的响应是终止该守护者,从而关闭整个actor系统.
/system: 系统守护者
这个特殊的守护者是为了保障正确的关闭顺序,即日志(logging)要保持可用直到所有普通actor终止,即使日志本身也是用actor实现的.其实现方法是: 系统守护者会一直观察(Watch)user守护者,直到收到Terminated消息,之后它开始初始化它自己的关闭过程.顶级的系统actor被监管的策略是,对收到的除ActorInitializationException 和 ActorKilledException之外的所有Exception无限地执行重启,这也将终止其所有子actor.所有其他Throwable被上报,然后将导致整个actor系统的关闭.
/: 根守护者
根守护者是所有所谓顶级actor的祖父,它监督所有在Actor路径的顶级作用域中定义的顶级actor,使用发现任何Exception就终止子actor的SupervisorStrategy.stoppingStrategy策略.其他所有Throwable都会被上报……但是上报给谁?所有的真实actor都有一个监管者,但是根守护者没有父actor,因为它就是整个树结构的根.因此这里使用一个虚拟的ActorRef,上报给它(类似JVM的classLoader体系),在发现问题后立即停掉其子actor,并在根守护者完全终止之后(所有子actor递归停止),立即把actor系统的isTerminated置为true
顶级actor
根守护者是祖父节点、守护者和系统守护者是父节点,下面才是所谓的顶级actor包括你在守护者下面用ActorSystem.actorOf创建的actor,这里才是你的世界,人外有人,你的世界之上还有两层呢.系统守护者下面是系统创建的actor包括日志监听、配置的系统启动自动创建的actor;其他的父节点还有: 死信节点(deadLetters): 接收所有死信dead letter的actor;临时节点(temp)监管所有系统创建的临时actor比如ActorRef.ask创建的;远程(remote),它下面是所有监管者是远程actor的actor.
重启的含义
The ability to do this is one of the reasons for encapsulating actors within special references. The new actor then resumes processing its mailbox, meaning that the restart is not visible outside of the actor itself with the notable exception that the message during which the failure occurred is not re-processed.
当一个actor失败重启了,则它的所有ActorRef也会被更新,这种能力是设计ActorRef的重要原因(参考远程Rremoting的定义要求,AKKA要求P2P对等通讯,似乎也有这方面的原因,因为actor和actorRef必须能够做到双向主动通讯,这和传统OO的对象与对象引用之间的关系本质上不同,可以理解为actor和actorRef实际上是对等的可以互相通讯的独立对象),新创建的actor接着就会重新开始处理它自己的邮箱(这里也有重点,就是原actor尚未来得及处理的消息是否能得到继续处理呢?下面解释),这个过程意味着重启在actor外部是不可见的、完全透明的,外部是看不到这个actor重启了的,因为外部没感觉到消息得不到处理的异常情况.可以明确: 原actor的消息会得到继续处理、不会丢失,邮箱是属于ActorSystem而非actor的,赞!
Monitoring/Watch守望
如上所述,监管是父子间的特殊关系,除此以外,任意一个actor都可以观察(Watch)任意一个actor,Watch的含义是: 由于actor从创建开始就是活跃的,而且其重启除了直接监管者,在外部都是不可见的,所以所谓的观察(Watch)就只能监视一件事: 死亡、或者说从活跃到死亡的状态转移.Watch就是绑定了两个actor,被监视者的死亡会给监视者发出Terminated消息通知,Terminated消息定义在Actor库内,不可转发而且属于本地(同一个JVM)消息,对应的远程消息是DeathWatchNotification.
这种机制又叫Death Watch——死亡观察,估计是因为只能监视死亡.调用ActorContext.watch(targetActorRef)开始观察, I Watch your Death.
